Lets take a moment to revise everything so far;
- We learnt that we tend to reward good behaviour while reprimanding unfavourable ones.
- We learnt that states represent the factors which influence a person’s decision.
- We learnt that the most recent state effects the players future decisions more than previous states
The actual computer
Now to the dirty business, how shall we make this computer? We saw that the states are independent of each other and primarily a decision is based purely out of the most recent state, so it makes sense to have containers of all the possible states. How will we make a decision for the next possible state? Let’s imagine that each of these containers contained the probability of making a future decision. That is they contained information regarding which move to play next in the form of probability. Now how shall we represent this probability, the answer is quite simple, let’s pick differently coloured balls from a closed bad.
The computer is slowly taking shape, we now have to add the algorithm for rewarding and reprimanding. The game ends in three scenarios for any player { Win, Loss, Draw}. When we win let’s reward the computer by increasing the probability that he wins again. How do we do that you may ask? Well we can do two things, either increase the number of the particular colour balls in the bag or decrease the other colour balls in the bag. Just because it’s rewarding let’s choose the first option of increase coloured ball count. Though I would be very happy to study what happens in the other scenario too. At the same time let’s reprimand the computer by removing balls of the particular colour whenever it loses. Draw seem to be a slightly more positive reward than a negative one, so lets reward it by increasing the coloured ball count but not by as much if it had won.
The architecture of the computer has been deveolped now what are the equivalent parts?
- The containers are matchboxes.
- The balls are different coloured beads representing each move possible.
- A reward is provided by increasing the number of coloured bead by 3.
- For example: if in state:01 the red bead is picked and the game is terminated as a win by MENACE we add 3 additional red coloured beads in the respective state:01 box.
- Similarly a reprimand is accomodated by decreasing the number of coloured bead by 1.
- For example: if in state:01 a green bead is picked and the game terminates as a loss to MENACE we remove the picked green bead from the respective state:01 box.
- A draw is considered by rewarding the coloured bead by 1.
Resources
At this point I would like to point out to the additional resources and links provided on the right mainly being [6] . The link provides data in the form a social experiment where a MENACE was played against the general public at the Manchester science festival. Videos [4,5] were made by one of my favourite all time authors [Humble Pi] and video maker Matt Parker. I hope to make my own graphs in the very near future using.
Observations
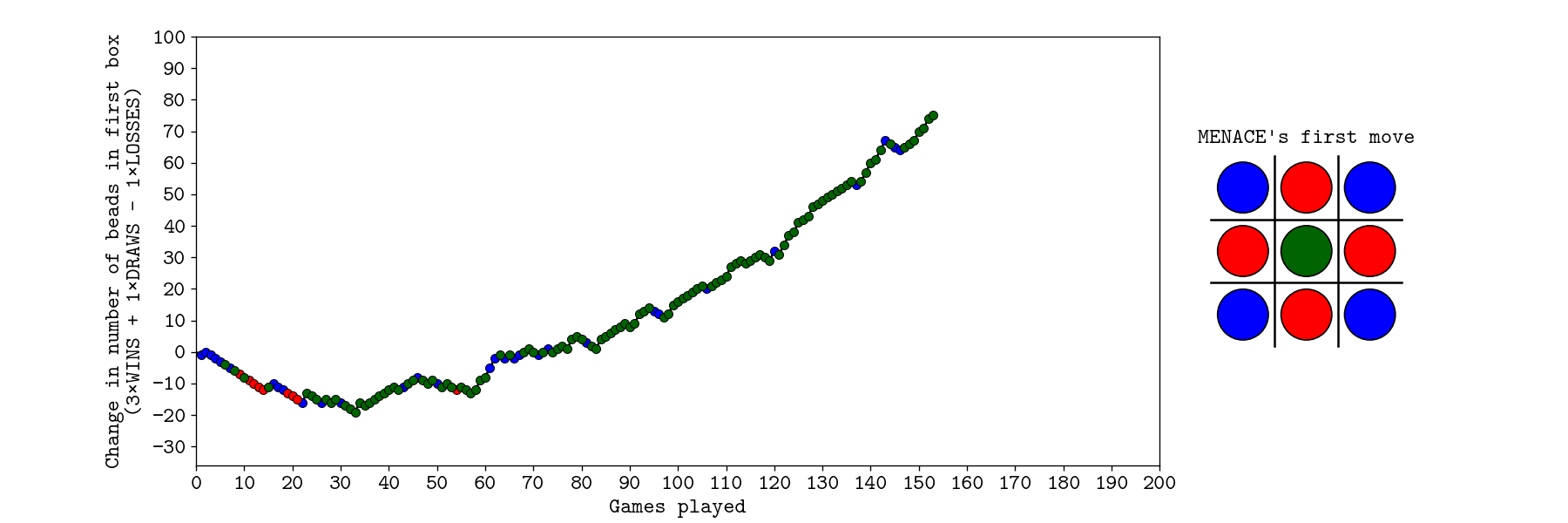
The diagram above shows the count “total number of beads” in the first move box of MENACE. At the same time the coloured dots represent which bead was picked by random during operation. We notice an initial dip in the count during the first 30 games. Further there appears to be no red beads picked following the 25th game. The gradual increase in the number of beads are seen to be primarily in green colour.
There are slight discrepancies in the form that there was a single red bead picked around the 50th game. I would like to bring to notice that small changes in peaks occured whenever a blue bead was picked.
Interpretation
The diagram’s observation provides crucial data on questions such as;
- How quickly did MENACE learn?
- What was the strongest move?
- What is the weakest move?
- How many games did it take to start winning?
At the same time we could question ourselves on topics such as;
- How can we make it learn faster?
- Was the strongest move dependent on other factors?
- Was the weakest move dependent on other factors?
- Chat can we change to make it win faster?
The initial dip in the first 30 games is attributed to MENACE slowly learning the good and bad moves to be made. We might be able to tweak this by changing reward and reprimand numbers appropriately.
No red beads being picked after the 25th game points that this strategy almost always results in an unfavourable outcome, while a centre bead is favourable. This is sensible as a centre bead allows 4 ways to make a line of three thus giving the best chance of winning.
Small dips following the blue beads being picked is a direct result of losing edge picked games. This is backed by the fact that an edge picked bead will only have 2 ways to make a line of three, thus being the suboptimal strategy of winning.
A question arises why the corner bead is the first to be removed. I believe this is a result of the human player playing a centre move following the corner move thus blocking the corner piece immediately. It would be interesting to notice what would happen if we force an edge move to be played during the same game.
Conclusion
The device learns within a span of 25 games to play the centre move whenever it starts first, granted that the opponent is playing with a desire to win and is not always perfect. There are methods to vary how quickly MENACE learns and techniques to “cheat” the system in this version of MENACE but the building blocks for self learning are set in the forms of probabilities.
I am just fascinated by this simple yet beautiful device. I believe this is one of the most basic building blocks of a simple learning machine. It provides a platform to discuss and search in to different techniques to answer the above questions mentioned. I hope to work with the data mentioned above and provide my own graphs in the near future. I hope to incorporate a computer and mechanical based version of MENACE soon in the website.