The Matchbox Educable Noughts and Crosses Engine (MENACE)is a mechanical computer made from 304 matchboxes designed and built by Donald Mitchie in 1961.
What?
During world war II when computers were essentially mechanical devices and women crunching numbers, there was an interest to make a computer to learn by itself. Eager to demonstrate artificial intelligence through “trial and error learning” in simple mental games he constructed a device out of matchboxes to test out his algorithms.
The Idea
Copying one of his paper’s paragraph [2] :
"A reason for being interested in games is that they provide a microcosm of intellectual activity in general. Those thought processes which we regard as being specifically human accomplishments learning from experience, inductive reasoning, argument by analogy, the formation and testing of new hypotheses, and so on are brought into play even by simple games of mental skill. The problem of artificial intelligence consists in the reduction of these processes to the elementary operations of arithmetic and logic."
One can imagine the game as a “sequential decision” process, the sequence of choices made during the various “states” of the game result in an outcome. The outcome then being assigned a value, (much like John Nash’s theory of utility) which determines how fruitful the previous desicions are. As the device learns from past experiences it receives reinforcements on what is good and bad.
Analogy to teaching a puppy
I love to take the analogy of teaching a puppy to sit. In the following paragraphs I will consider the dog as a subject. A typical method of teaching involves repeating the words “sit” and helping the dog complete the action by forcibly moving his body. As the action is completed we reward him with a treat or reprimand him if he fails to repeat the action. The algorithm descibed in MENACE does the same, where the choices of sequential decisions are rewarded if they result in a beneficial outcome. At the same time the choices are reprimanded given that the outcome is non beneficial.
States
I find this topic a little more challenging to explain. Lets use the noughts and crosses (tic-tac-toe) as an example itself. Let there be two players playing the game with their legend as in the picture below. Let us consider a more drastic situation in which the game is being played. Assume that the two players have never met each other (thus they don’t have any psychological knowledge or previous experience). Both the players are now in two separate rooms with zero contact with each other. A third room consists of the game board, each player on their turn exits their room and enters the game room and plays their move following which they return back to their respective rooms awaiting the oppositions move.
From the situation described above we define a state of the board as the state of the board just before a decision a player plays his move. The below picture describes one such game being played.
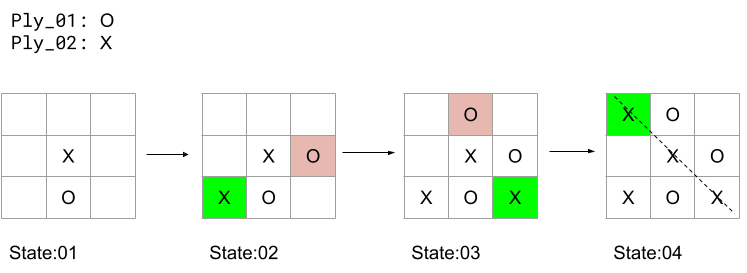
In the diagram above player01 plays first always and player02 notices the state of the board without the green box, he/she eventually plays their move in response to state:– at the green box.
Suppose player02 is yet to play in state:03(horrible punctuation), the player believes that the best possible option for him is with index (1,1) i.e the green box in state:04 and plays that option. On questioning why player plays that option he answers “state:03 presented me with the best option to play, I could either do index(1,1), index(1,3), index(2,1) or index(3,3) (essentially all empty spots). They decide to attempt index(3,3) because they notice the game can be ended favourably within the next state(though notably other indices might help in the same too)”. I bring to notice that the player informs about the most recent state and doesn’t point out about previous state events having majorly affecting his decision.
The point made above is important, though sounding trivial it is important to understand that we put more emphasis on the most recent states than any previous states. In other words the most recent event is more important than historic events. Again taking an excerpt from the article by Dr Michie:
"This picture of trial-and-error learning uses the concepts and terminology of the experimental psychologist. Observations on animals agree with common sense in suggesting that the strength of reinforcement becomes less as we proceed backwards along the loop from the terminus towards the origin. The more recent the choice in the sequence, the greater its probable share of responsibility for the outcome. This provides an adequate conceptual basis for a trial-and-error learning device, provided that the total number of choice-points which can be encountered is small enough for them to be individually listed."
But learning over several thousands if not millions of such games will help in learning over all the possible situations of the game as this small weightage slowly creeps to astonishing values in the initial stages of the game. One might ask, how can we teach the computer to learn over a thousand games rather than a million? Or When do we know that the computer has learnt sufficiently enough? These are important questions to be answered hopefully in a future post. Lastly I bring to notice that this is backed by previous studies of animals and commonsense, there might be different mathematical methods to improve this value based jump we have considered here. (needs input)
A revision so far
Lets take a moment to revise everything so far;
- We learnt that we tend to reward good behaviour while reprimanding unfavourable ones.
- We learnt that states represent the factors which influence a person’s decision.
- We learnt that the most recent state effects the players future decisions more than previous states
The actual computer
Now to the dirty business, how shall we make this computer? We saw that the states are independent of each other and primarily a decision is based purely out of the most recent state, so it makes sense to have containers of all the possible states. How will we make a decision for the next possible state? Let’s imagine that each of these containers contained the probability of making a future decision. That is they contained information regarding which move to play next in the form of probability. Now how shall we represent this probability, the answer is quite simple, let’s pick differently coloured balls from a closed bad.
The computer is slowly taking shape, we now have to add the algorithm for rewarding and reprimanding. The game ends in three scenarios for any player { Win, Loss, Draw}. When we win let’s reward the computer by increasing the probability that he wins again. How do we do that you may ask? Well we can do two things, either increase the number of the particular colour balls in the bag or decrease the other colour balls in the bag. Just because it’s rewarding let’s choose the first option of increase coloured ball count. Though I would be very happy to study what happens in the other scenario too. At the same time let’s reprimand the computer by removing balls of the particular colour whenever it loses. Draw seem to be a slightly more positive reward than a negative one, so lets reward it by increasing the coloured ball count but not by as much if it had won.
The architecture of the computer has been deveolped now what are the equivalent parts?
- The containers are matchboxes.
- The balls are different coloured beads representing each move possible.
- A reward is provided by increasing the number of coloured bead by 3.
- For example: if in state:01 the red bead is picked and the game is terminated as a win by MENACE we add 3 additional red coloured beads in the respective state:01 box.
- Similarly a reprimand is accomodated by decreasing the number of coloured bead by 1.
- For example: if in state:01 a green bead is picked and the game terminates as a loss to MENACE we remove the picked green bead from the respective state:01 box.
- A draw is considered by rewarding the coloured bead by 1.